Sharing thoughts and ideas
nullptr Over 0 or NULL in C++In modern C++, there are three common methods to check if a pointer is null: comparing it to 0, NULL, or nullptr. Among these, nullptr is the recommended approach. But what makes nullptr the preferred choice over the more traditional 0 or NULL?
0 Nor NULL Are PointersThe literal 0 is of type int, not a pointer. When used in a context where a pointer is expected, it is interpreted as a null pointer. However, 0 remains an int, not a pointer type.
NULL can vary by implementation and may be of type int or another integer type, such as long. The core issue remains: NULL is not a pointer type but an integer type.
Consider the following code snippet:
#include <iostream>
using namespace std;
/// With overloads (1)
void f(int) { cout << "f1 called" << endl; }
void f(long) { cout << "f2 called" << endl; }
void f(void*) { cout << "f3 called" << endl; }
// No overloads
void g(void*) { cout << "g called" << endl; }
// WIth overloads and potential implicit conversion (form long to int)
void h(int) { cout << "f1 called" << endl; }
void h(bool) { cout << "f2 called" << endl; }
void h(void*) { cout << "f3 called" << endl; }
int main() {
f(0); // calls f(int)
f(NULL); // May not compile, could call f(int)
f(nullptr); // calls f(void*)
int* my_function = NULL;
f(my_function); // No overload: Invoking the right function
g(0); g(NULL); g(nullptr); // Calls g(void*)
h(0); // Calls h(int)
h(nullptr); // Calls h(void*)
}
Here is the output (link to compiler explorer):
f1 called
f2 called
f3 called
f3 called
g called
g called
g called
f1 called
f3 called
0 or NULL as parameters in overloaded functions can lead to unexpected behavior:f(0) calls void f(int) instead of void f(void*).f(NULL) calls void f(long) instead of void f(void*).
Ambiguous Call: When NULL is defined as 0L (long type), and there is an overload for int but not for long, the compiler may throw an error due to ambiguity. This occurs when uncommenting h(NULL) in the code above:
text
**<source>:27:6:** **error:** call of overloaded function 'h(NULL)' is ambiguous
27 | h(NULL);
| ~^~~~~~
nullptr Is BetterType Safety: nullptr is defined as std::nullptr_t, which can implicitly convert to any raw pointer type. It acts as a pointer of any type.
Avoids Overload Issues: Using nullptr avoids the ambiguity and issues associated with overloaded functions.
Clarity: It makes the code clearer. For example, if (res == nullptr) { ... } clearly indicates that res is being tested for nullity, whereas if (res == 0) { ... } could be ambiguous.
Template Type Deduction: In C++, template type deduction infers the types of arguments. nullptr allows for precise deduction of a pointer type.
Consider this templated function:
#include <iostream>
using namespace std;
template <typename T>
void printType(T* ptr) {
cout << "Pointer to type: " << typeid(ptr).name() << endl;
}
0 or NULL: These cannot clearly indicate a pointer type in the template, leading to ambiguity:```c++ int main() { printType(0); // Ambiguous - 0 can be treated as integer or pointer printType(NULL); // Ambiguous - NULL is typically 0 }
- **Using `nullptr`**: There is no ambiguity, as it explicitly represents a pointer:
```c++
int main() {
printType(nullptr); // No ambiguity, nullptr is treated as a pointer type
}
In summary, nullptr is the preferred approach because it is explicitly treated as a pointer type, avoiding the ambiguity that 0 or NULL can introduce, especially when dealing with overloaded functions and templates involving pointer types.
C++
Rust: Comparative analysis withC++This article aims to provide an analysis of Rust ownership and related concepts for programmers with experience in C++.
Borrowing a value means having a reference to the value without owning it.
Taking ownership of a value means becoming the new owner of the value.
let m_str = "Hello, World".to_string(); // m_str owns the value
let m_str_ref = &m_str; // m_str_ref borrows the value
let m_str2 = m_str; // m_str2 becomes the new owner, m_str is invalidated.
println!("{}", m_str_ref); // Ok: It is a reference
println!("{}", m_str2); // Ok: It is the new owner
println!("{}", m_str); // Error: Ownership has moved to m_str2.
// The binding of m_str has been dropped (moved to m_str2)
clone() method.Ruststd::rc::Rc<T>Rc<T> is a smart pointer that allows multiple ownerships. If you’re familiar with C++, std::rc::Rc<T> is similar to std::shared_ptr<T>.
Both:
- Use a reference-counting mechanism to manage heap-allocated data.
- Automatically deallocate the object when the last reference is dropped.
- Cloning or copying an Rc<T> creates a new reference to the same object and increases the reference count. Similarly, copying a shared_ptr<T> does the same.
Let's look at an example in Rust to demonstrate multiple ownership.
See this example on Compiler Explorer here.
use std::rc::Rc; // Import reference counter
fn main() {
let owner = Rc::new(8); // Create a new reference counter
println!("Owners: {}", Rc::strong_count(&owner));
{ // Closure
println!("New closure (1)");
let _owner2 = owner.clone();
println!("Owners: {}", Rc::strong_count(&owner));
{ // Another closure
println!("New closure (2)");
let _owner3 = owner.clone();
println!("Owners: {}", Rc::strong_count(&owner));
println!("Leave closure (1)");
}
println!("Owners: {}", Rc::strong_count(&owner));
println!("Leave closure (2)");
}
println!("Owners: {}", Rc::strong_count(&owner));
}
Running this program gives the following result:
Owners: 1
New closure (1)
Owners: 2
New closure (2)
Owners: 3
Leave closure (1)
Owners: 2
Leave closure (2)
Owners: 1
This illustrates two things: - The reference counter increments when adding a new owner. - The reference counter decrements when the program leaves the scope of an owner.
std::rc::Rc<T> and std::shared_ptr<T>| Feature | Rc<T> (Rust) |
std::shared_ptr<T> (C++) |
|---|---|---|
| Thread Safety | Not thread-safe (modifying the reference count at the same time can cause data races and undefined behavior). Arc<T> is used for multi-threading. |
Thread-safe for reference counting (atomic operations). Not thread-safe for managed T object (needs to use mutex). |
| Performance | Faster (no atomic operations) | Slightly slower (due to atomic reference counting) |
Box<T>Box<T> provides ownership of heap-allocated data and ensures that the data is deallocated when the Box goes out of scope.
Box<T> is comparable to C++ std::unique_ptr<T>:
- Both enforce unique ownership.
- C++ is less strict, as it doesn't detect moved ownership at compile time:
Here’s an example showing a runtime error in C++ when trying to access a moved value:
#include <memory>
#include <iostream>
using namespace std;
int main() {
auto ptr1 = make_unique<int>(10);
cout << "Ptr1 value: " << *ptr1 << endl;
auto ptr2 = move(ptr1);
cout << "Ptr2 value: " << *ptr2 << endl;
// Trying to access ptr1 after the move
// Compiles, but causes a SIGSEGV error (runtime error)
cout << "Ptr1 (2) value: " << *ptr1 << endl;
}
In comparison, the following Rust code won’t compile at all:
fn main() {
// Create a `Box` to hold an integer on the heap
let ptr1 = Box::new(10);
println!("Ptr1: {}", *ptr1);
let ptr2 = ptr1;
println!("Ptr2: {}", *ptr2);
println!("Ptr1 (2): {}", *ptr1); // Compile error
}
This results in the following error message:
error[E0382]: borrow of moved value: `ptr1`
--> <source>:16:29
|
12 | let ptr1 = Box::new(10);
| ---- move occurs because `ptr1` has type `Box<i32>`, which does not implement the `Copy` trait
13 | println!("Ptr1: {}", *ptr1);
14 | let ptr2 = ptr1;
| ---- value moved here
15 | println!("Ptr2: {}", *ptr2);
16 | println!("Ptr1 (2): {}", *ptr1);
| ^^^^^ value borrowed here after move
Arc<T>Arc<T> is used to enable shared ownership of data between multiple threads. The reference count is atomically updated, making it safe for concurrent access.
- Thread-safe (atomic reference counting), unlike Rc<T>.
- It is immutable by default.
Here’s an example using Arc in a multi-threaded context:
use std::sync::Arc;
use std::thread;
fn main() {
let value_ptr = Arc::new(5);
let value_ptr_clone = Arc::clone(&value_ptr);
let handle = thread::spawn(move || {
println!("Inside thread, value: {}", value_ptr_clone);
});
handle.join().unwrap();
println!("Main thread, value: {}", value_ptr);
}
Arc<T> doesn’t allow direct mutation of the value because it is immutable by default. This is a major difference compared to C++, where mutable data can be shared across threads. Rust’s emphasis on immutability helps eliminate the risk of modifying the same value from different threads.
Mutex<T> for MutabilityTo modify a value within a thread, we need to combine Arc<T> with a Mutex<T> (or RwLock<T>, though we won’t cover RwLock here). With Mutex<T>, we must lock the value inside the thread before making any modifications. Below is an example using Arc<Mutex<T>>:
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let value_mutex_ptr = Arc::new(Mutex::new(5)); // Using Mutex inside Arc
let value_mutex_ptr_clone = Arc::clone(&value_mutex_ptr);
let handle = thread::spawn(move || {
let mut data_mutex = value_mutex_ptr_clone.lock().unwrap(); // Lock the mutex
*data_mutex = 42; // Modify the value
println!("Inside thread: {}", *data_mutex);
});
handle.join().unwrap();
let data_mutex = value_mutex_ptr.lock().unwrap();
println!("Inside main thread: {}", *data_mutex);
}
Rust to take ownership of a value and borrow a value.std::rc::Rc<T>, a smart pointer that allows multiple ownership through reference counting. It is efficient but not designed for multi-threading.std::sync::Arc<T> to share ownership across threads. Arc<T> is immutable by default.Arc<T>, we combine it with Mutex<T> (e.g., Arc<Mutex<T>>).Rust C++
This article aims to provide a clear understanding of how we can optimize the use of strings in C++ to improve performance. It does not discuss when to optimize, as that is a separate topic.
std::string is not a primitive type. It has behaviors that make it expensive to use, regardless of the implementation. The main issue with strings is that they are dynamically allocated but behave as values in expressions, leading to excessive copying.
std::string needs to grow dynamically to accommodate its content, unlike fixed-size character arrays (char[]). To implement this flexibility, it uses dynamic memory allocation.
A string object contains a small internal buffer of fixed size, located on the stack. If the content does not exceed this size, the string does not need to allocate memory. However, once it exceeds the buffer size, the string allocates memory on the heap instead of using local storage. This mechanism is known as Small String Optimization (SSO).
The size of the local buffer is implementation-dependent. However, typical values are: | Compiler | SSO Buffer Size (bytes)| | ---- | ---- | | GCC (libstdc++) | 15 | | Clang | 22 or 23 | | MSVC | 15 |
To check the size of the SSO buffer, we can incrementally add characters to a string and monitor when its capacity changes:: Compiler explorer link here.
#include <iostream>
#include <string>
using namespace std;
int main() {
std::string s;
std::size_t capacity = s.capacity();
for (int i = 1; i < 100; ++i) {
s += 'a'; // Add characters one by one
if (s.capacity() != capacity) { // Detect capacity increase
std::cout << "SSO buffer size: " << i - 1 << " bytes\n";
break;
}
}
return 0;
}
Assigning one string to another behaves as if each string variable has a private copy of its content.
int str1, str2;
str1 = "Hello"
str2 = str1;
str2[4] = '!';
// Will print "Hello", not "Hell!"
std::cout << str1 << std::endl;
Since strings also support mutating operations, they must behave as if they have private copies of their content. This results in copying when:
Before C++11, COW was used to optimize memory usage. Two strings could share the same dynamically allocated storage until one of them performed a mutating operation, at which point a new allocation was triggered.
Since C++11, COW is officially forbidden due to issues in multi-threaded environments. Modern C++ requires that std::string::data() return a mutable pointer (char*), which is incompatible with COW. Consequently, deep copies are now required.
While COW saves memory, it is unsafe in multithreaded environment when multiple threads modify the same string. It also adds overhead* for reference counting and atomic operations.
In modern C++ (11+), the standard requires string to have the method data() , that must return a mutable pointer (char*). This requirements is not compatible with COW.
Now, strings are required to use deep copy instead of COW.
// Old possible behavior with COW
#include <string>
std::string str1 = "Hello";
std::string str2 = str1; // No copy, reference count
str2[0] = 'h'; // Will trigger deep copy due to mutating operation
// Modern c++
std::string str1 = "Hello";
std::string str2 = str1; // Actual copy, no reference counting
str2[0] = 'h'; // Already independent.
Now that we have seen what ar ethe issues with Strings in C++, and got an overview how is composed a string, we can now dive into the ways to optimize the usage of it inside our code.
Mutating operations do not rely on value semantics, which means they avoid unnecessary copies. Using mutating operations instead of expensive copy-based operations is an efficient way to improve performance.
Instead of using string operations that are costly, we can opt for mutating operations that do not involve dynamic memory allocation.
#include <iostream>
#include <string>
using namespace std;
string remove_symbols(std::string str) {
string res;
for (int i = 0; i < str.length(); ++i) {
if (str[i] != ',' && str[i] != ';') {
// String contatenation operation is expensive
// The contatenated string is hold in a newly created
// temporary string
res = res + str[i];
}
}
return res;
}
int main() {
std::string original = "Hello, World;";
auto res = remove_symbols(original);
cout << res << endl;
return 0;
}
#include <iostream>
#include <string>
using namespace std;
string remove_symbols2(std::string str) {
string res;
for (int i = 0; i < str.length(); ++i) {
if (str[i] != ',' && str[i] != ';') {
res += str[i]; // This avoids the copy in the loop
}
}
return res;
}
int main() {
std::string original = "Hello";
modifyStringInPlace(original);
cout << "String : " << original << endl;
return 0;
}
Running it in a benchmark quick-bench link , even using -O3 optimization flag show drastic performance improvement:

reserve()Using reserve can avoid the number of reallocation. Indeed, when adding content to the string, if the capacity if the buffer is exceeded, it will reallocate a bigger buffer ( usually doubling the capacity), and do a copy of all the content to the new buffer.
To avoid these reallocation,
reserve()std::vector<int> vec;
for (int i = 0; i < 1000000; ++i) {
vec.push_back(i); // Will cause multiple reallocations
}
reserve()std::vector<int> vec;
vec.reserve(1000000); // Pre-allocate mem. for 1 million elements
for (int i = 0; i < 1000000; ++i) {
vec.push_back(i);
}
const string& instead of string in arguments of a functionPassing by reference avoids copying the string, and can have significant performance improve, especially for large strings.
In the following code, we force a copy inside the functions. This is done because when the function only reads the string and doesn't copy it inside, the compiler might inline the function and optimize the difference away.
// Pass by value
void pass_by_value(std::string str) {
std::string copy = str; // Forces a copy
benchmark::DoNotOptimize(copy);
}
#include <string>
// Pass by reference
void pass_by_reference(const std::string& str) {
std::string copy = str; // Forces a copy inside
benchmark::DoNotOptimize(copy); // Prevent optimization
}
We use this code to benchmark: ( quick-bench link here )
// Benchmark for pass by value
static void BM_pass_by_reference(benchmark::State& state) {
std::string original(10000, 'x'); // 10,000 characters
for (auto _ : state) {
benchmark::DoNotOptimize(original);
pass_by_reference(original);
}
}
// Benchmark for pass by const reference
static void BM_pass_by_value(benchmark::State& state) {
std::string original(10000, 'x');
for (auto _ : state) {
benchmark::DoNotOptimize(original);
pass_by_value(original);
}
}
// Register benchmarks with different string sizes
BENCHMARK(BM_pass_by_reference);
BENCHMARK(BM_pass_by_value);
The result shows significant performance increase when passing by reference.
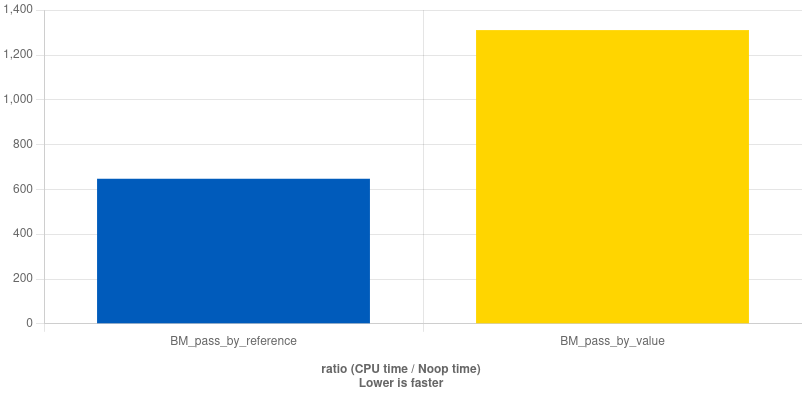
We have covered some important optimizations for strings, but is it not exhaustive. Some other things that can be check are :
- Avoid copying in returned values
- Use char* or char[] instead of string
- Using iterators instead of loops to avoid dereferences
- Use better string library (boost)
- Custom implementation (fbstring)
- stringstreamto avoid value semantic
- string_view
- Avoid string conversion ( C-type strings and C++ string)
- Use better algorithms
Optimizing string usage in C++ is crucial for improving the performance of applications that heavily rely on string manipulation. We’ve explored the main issues related to std::string, such as dynamic memory allocation, excessive copying, and the implications of Small String Optimization (SSO) and Copy-On-Write (COW) in different C++ standards. Through examples, we highlighted how mutating operations, proper memory allocation via reserve(), and passing strings by reference rather than by value can greatly enhance performance.
By adhering to best practices like avoiding unnecessary copies, leveraging mutating operations, and using const std::string& in function arguments, C++ developers can significantly reduce memory overhead and improve the speed of their applications. While these optimizations are essential for writing efficient code, they are not exhaustive. Other techniques, such as using string_view, char* arrays, or even third-party libraries like Boost, can provide additional performance improvements based on specific use cases.
String optimization, as discussed in this article, is a powerful way to achieve higher efficiency, especially in performance-critical applications.
Guntheroth, Kurt. Optimized C++: Proven Techniques for Heightened Performance. Addison-Wesley, 2004.
Inside STL: The String. Microsoft. https://devblogs.microsoft.com/oldnewthing/20230803-00/?p=108532
Understanding Small String Optimization (SSO) in std::string. cppdepend.com. https://cppdepend.com/blog/understanding-small-string-optimization-sso-in-stdstring
Dicanio, Giovanni. The C++ Small String Optimization. giodicanio.com. https://giodicanio.com/2023/04/26/cpp-small-string-optimization
C++ Weekly - Ep 430 - How Short String Optimizations Work. YouTube. https://www.youtube.com/watch?v=CIB_khrNPSU
Optimization C++
into() in RustRust has several features that may seem unusual at first but serve an important purpose. One such feature is the into() method.
into() Do?into() is a method from the Into<T> trait that converts an object into a different type. Since Rust supports method overloading based on return type, the target conversion type is inferred from context.
For example:
// Conversion from int to float
let converted_value: f64 = 42.into();
According to the Rust documentation, into() performs a value-to-value conversion and is conceptually the opposite of From.
From<T> vs Into<U>From<T> Automatically Provides Into<U>?When implementing From<T> for U:
// Implementing From<T> for type U
trait From<T> {
fn from(value: T) -> Self;
}
This provides a way to convert T into U. Rust then automatically provides an implementation of Into<U> for T:
// Into<T> for type U
trait Into<T> {
fn into(self) -> T;
}
Rust offers a blanket implementation of Into in terms of From, meaning Into is always available when From is implemented:
impl<T, U> Into<U> for T
where
U: From<T>,
{
fn into(self) -> U {
U::from(self)
}
}
Compiler Explorer link: here
struct Point {
x: i32,
y: i32,
}
impl From<i32> for Point {
fn from(value: i32) -> Self {
Point { x: value, y: value }
}
}
fn main() {
let num: i32 = 7;
let p: Point = Point::from(num);
let p2: Point = num.into(); // Automatically available
println!("p = ({}, {})", p.x, p.y);
println!("p2 = ({}, {})", p2.x, p2.y);
}
From<T> and Into<U>From<T> is explicitly implemented and defines how to convert T into a target type U.Into<U> is automatically available when From<T> is implemented for U, allowing the use of .into()..into() Over From::from()When writing generic code, the exact target type may not be known in advance. .into() offers more flexibility.
fn convert_to_f64<T: Into<f64>>(value: T) -> f64 {
value.into() // Works with any type that implements Into<f64>
}
From::from()fn convert_to_f64<T>(value: T) -> f64 {
f64::from(value) // Error: Rust cannot guarantee that f64::from(T) exists for all types
}
If the context already defines the target type, .into() keeps the code concise:
let num: i32 = 42;
let float_num: f64 = num.into(); // Rust infers the target type as f64
// Also works, but longer
let float_num2: f64 = f64::from(num);
However, if the target type is not known, .into() will not work:
let float_num = num.into(); // Error: target type cannot be inferred
When multiple types can be converted to a target type, .into() allows for a wider range of inputs.
struct Distance(f64);
impl From<i32> for Distance {
fn from(value: i32) -> Self {
Distance(value as f64)
}
}
impl From<f32> for Distance {
fn from(value: f32) -> Self {
Distance(value as f64)
}
}
fn print_distance<T: Into<Distance>>(value: T) {
let d: Distance = value.into();
println!("Distance: {}", d.0);
}
fn main() {
print_distance(10); // Ok
print_distance(5.5_f32); // Ok
}
.into()You should not use .into() if you don’t need ownership. Instead, consider:
&T)AsRef<T> (for read-only borrowed conversions).clone() or .to_owned() (to create a copy)Copy trait (for lightweight types)Additionally, avoid .into() when the target type is unclear. In such cases, explicit conversion using From::from() or as is preferable.
into()Since Into<T> is a value-to-value conversion, the value is consumed. However, for primitive types implementing Copy, the value is not moved but copied:
let v_a: i32 = 43;
let v_b: f32 = v_a.into();
println!("v_a = {}", v_a); // Still valid
println!("v_b = {}", v_b);
For non-Copy types like String, the value is moved:
let v_a = String::from("hello");
let v_b: String = v_a.into();
// println!("v_a = {}", v_a); // Error: value has been moved
println!("v_b = {}", v_b);
.into() in StructsA common pattern is accepting impl Into<String> parameters in constructors:
struct User {
name: String,
surname: String,
}
impl User {
fn new(name: impl Into<String>, surname: impl Into<String>) -> Self {
User { name: name.into(), surname: surname.into() }
}
}
fn main() {
// Conversion from `&str` to `String`
let user1 = User::new("Albert", "Einstein");
// Directly passing a `String`: no conversion
let user2 = User::new(String::from("Satoshi"), String::from("Yamamoto"));
}
From<T> explicitly defines how to convert T into U.Into<U> is automatically available when From<T> is implemented..into() when writing generic code, when the target type can be inferred, or to allow multiple input types..into() if ownership is not needed or when the target type is unclear.Rust Documentation
Rust's standard library documentation on the Into trait.
Link: Rust Documentation - Into Trait
The Rust Programming Language - Chapter 10
The official Rust book's chapter on conversion traits like From, Into, AsRef, and ToOwned.
Link: The Rust Programming Language - Conversion Traits
Rust by Example - Conversions
Practical examples and code snippets on conversions between types in Rust.
Link: Rust by Example - Into Trait
Rust
A well-designed database is essential for any database project. It ensures data integrity, minimizes redundancy, enhances application performance, and improves user satisfaction—all critical factors for a successful project.
Investing time in database design is mandatory, as it helps prevent costly issues later in the project.
The database design process consists of three key steps:
Requirements Analysis
Logical Design
Physical Design
This is the initial phase, where you collaborate closely with stakeholders to gather and analyze real-world business requirements and policies. The primary goal is to identify base objects and their relationships.
For example, in a scenario where a Client purchases a Product, we need to determine the relevant information associated with each entity. A Product may have attributes such as name and description, while a Client may have attributes such as name, client ID, address, email, and phone number. Also, A Client buying a Product involves creating a Purchase Order that contains Order Line Items.
A Client represents an individual or business making purchases. Relevant information includes:
ClientID (unique identifier)
FullName (first and last name or business name)
Address (including street, city, state, and zip code)
Email (primary contact email)
PhoneNumber (primary contact number)
RegistrationDate (date the client was added to the system)
A Product represents an item available for purchase. Relevant details include:
ProductID (unique identifier)
Name (product name)
Description (brief details about the product)
Price (cost of the product)
StockQuantity (number of available units)
Category (classification of the product)
A Purchase Order represents a transaction where a client buys one or more products. It includes:
OrderID (unique identifier)
ClientID (reference to the purchasing client)
OrderDate (date of purchase)
TotalAmount (total cost of the order)
PaymentMethod (e.g., credit card, PayPal, bank transfer)
An Order Line Item captures details of individual products within a purchase order:
OrderDetailID (unique identifier)
OrderID (reference to the related purchase order)
ProductID (reference to the purchased product)
Quantity (number of units purchased)
UnitPrice (price at the time of purchase)
There are several methods to collect and validate data:
Reviewing existing data stores as a source of information
Interviewing users to understand current data usage
Gathering insights from users to identify potential improvements
The result of the requirement analysis can be a report, a data diagram, or a presentation.
In this phase, the findings from the previous step are translated into Entities, Attributes, and Relationships:
Objects evolve into Entities
Object characteristics become Attributes
Relationships between objects are clearly defined
Entities should have well-structured attributes. For example, instead of storing an address as a single field, breaking it down into components such as street name, city, state, and zip code improves data efficiency and usability.
A solid logical design serves as the foundation for the physical database structure.
Assign a unique identifier as a primary key
Normalization to optimize data structure:
In OLTP (Online Transaction Processing) systems, normalization typically follows 3NF or higher to minimize redundancy.
In OLAP (Online Analytical Processing) systems, performance is prioritized, leading to denormalized schemas like the Star Schema for efficient querying.
In this final phase, the logical model is translated into an actual database structure. This involves defining tables, columns, data types, indexes, and storage requirements to ensure optimal performance and maintainability.
Entities identified in the logical design become tables.
Attributes are mapped to columns with appropriate data types (e.g., VARCHAR, INT, DATE).
Constraints such as NOT NULL, UNIQUE, and CHECK are applied to maintain data integrity.
Primary keys ensure each record is uniquely identifiable.
Foreign keys establish relationships between tables and enforce referential integrity.
Indexes are created to enhance query performance, especially for frequently accessed columns.
Consider clustered and non-clustered indexes based on query patterns.
Large datasets can be partitioned to improve performance.
Choosing between row-based or column-based storage depends on the database workload (OLTP vs. OLAP).
Implement user roles and permissions to restrict unauthorized access.
Encrypt sensitive data and enable audit logging for compliance.
Database design is crucial for the success of a project. The process consists of three key steps:
Requirements Analysis: Identifying base objects, relationships, and business information.
Logical Design: Structuring data into entities and attributes while applying normalization.
Physical Design: Implementing the design into a database with well-defined tables and columns.
By following these steps, we ensure a structured, scalable, and efficient database system.
-Approach to Database Design - IBM Data Engineering - Coursera
Database
